
coursera 자연어 특화 과정 중 마지막 4번째 코스 Natural Language Processing with Attention Models 에 대해서 공부한 글입니다.
목차
1. Seq2Seq & Attention
2. Training an NMT with Attention
3. Evaluation for Machine Translation
4. Sampling and Decoding
1. Seq2Seq
NMT 기계번역 task 를 배우고 Seq2Seq model을 배운다. Seq2Seq 의 문제점과 해결을 소개한다.
(1) Seq2Seq
- Encoder(인코더), Decoder(디코더)에 RNN계역의 모델을 사용한다.
- 다양한 길이의 input/output 을 동일한 길이의 memory에 할당한다.
- -> 그래서 input 의 길이는 다양해도 상관 없음 (Maps variable-length sequence to fixed-length memory)
- LSTM & GRU 는 vanishing gradient problem을 어느정도 해결한 모델이다.
(2) Seq2Seq 의 문제점
Bottleneck (병목현상)

- 디코더의 처음이 되는 값이 인코더의 다음 hidden state 에 쌓이는데, 매번 같은 길이로 계속 쌓이기 때문에 시퀀스가 길어지면 문제가 생긴다. -> 시퀀스의 다음 단계가 더 중요하다고 판단한다. 따라서 입력 자체가 긴 길이일 때 문제가 생김
- 고정된 크기의 인코더 hidden state를 갖는 것은 시퀀스를 압축하기 어렵다.
- 결과적으로 variable-length sentence + fixed-length memory 특징은 시퀀스가 커질수록 모델의 성능이 저하되는 문제점을 가진다.
(3) Seq2Seq 문제 해결 -> Attention
Attention
인코더가 긴 길이의 시퀀스를 압축하는 것에 어려움이 있다는 것이 문제점 이기 때문에, 이를 해결하기 위해서 Attention 개념을 도입한다.

- 모델이 각 step 마다 특정 단어를 선택해서 집중하도록(focus) 만들면 된다. (무조건 마지막 단어가 아니라)
- 따라서 모델이 각 step 마다 단어에 집중할 수 있는 information 과정인 담긴 layer를 하나 더 추가해준다.
- 기계번역에서 한 단어가 완벽하게 다른 단어에 일대일로 대응하지 않기 때문에, 어느 단어를 더 집중해서 볼 건지 weight를 줘야한다. 이 가중치를 부여하는 레이어가 필요한데, attention이다.
- alignment vector 를 계산하고 모두 더해서 context vector를 생성한다. -> 이 벡터가 디코더에 들어간다! (아래그림)
Alignment

Alignment(순서, 정렬) 의 개념은 기계번역에서 올바른 위치, 문맥 정도로 이해된다. a 언어 -> b 언어로 번역시에 각 단어의 위치는 바뀌게 된다. alignment를 학습함으로써 a 언어에서 b 언어로 번역할 때, 모호함을 해결할 수 있다. (attention mechanisam 으로 학습된 모델은 이런 대응 관계를 학습 할 수 있다.)
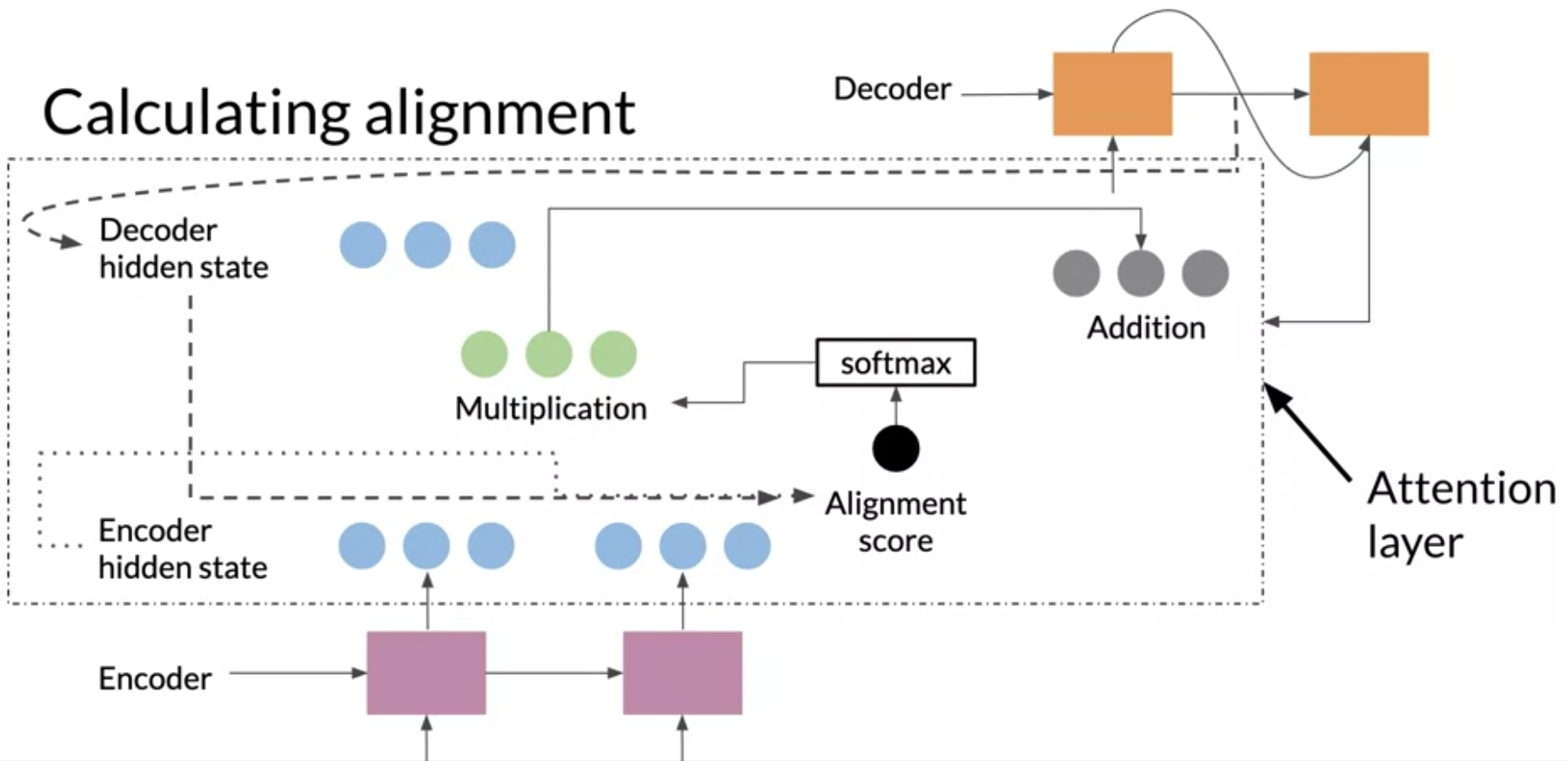
(여기서는 Alignment Score = Attention Score 이다.)
(3) Concept of attention for information retrieval
정보 검색을 위한 attention 개념에는 Key, Value, Query의 개념이 나온다.
attention context 에서 정보검색이 작동하는 방식은 다음과 같다.
방이 많은 복도에서 열쇠를 잃어버렸다. 그래서 열쇠를 찾기 위해 모든 방에 들어가 보는 것은 비효율적인 상태다.
그런데 엄마한테 찾는 것을 도와줄 수 있냐고 물었더니, 엄마는 보통 열쇠가 어디에 있는지를 알고 있었다. 그래서 열쇠가 어디에 있는지 모든 가능성생각하더니 가장 있을 것 같은 방을 알려줬다! 그리고 실제로 그 곳이 열쇠가 있는 곳이었다!
이게 attention이 하는 일이라고 한다.
쿼리를 수행하고, 키를 가지고 있을 확률이 높은 곳을 탐색한 후에 키를 찾는다!
- key 와 value 는 한 쌍이고, 둘다 인코더의 hidden state 에서 온다.
- 반면 query는 디코더의 hidden state 에서온다.
- 이 3개를 이용해서 attention 을 통과, key 와 query의 내적 연산이 구해진다.
- weighted value -> 각 값의 weighted value는 키가 쿼리와 일치할 확률 (0~1, softmax)
- 다음 쿼리가 다음 키 값으로 매핑된다. 여기까지를 scale dot product attention이라고한다.
Attention의 시각화와 공식
- Attention mechanism 을 시각화한 그림을 보면, 다른 언어로 기계 번역을 할 때 위치가 달라도 어디에 집중해서 봐야하는지 모델이 알고 있는 것을 볼 수 있다.
- Attention 모델은 다른 언어의 문법과 단어 순서의 차이를 처리할 수 있을 만큼 유연해야한다. (한국어와 영어의 명령어가 순서가 반대인 것을 포착할 만큼!)


단어의 Query(Q) 가 column, 단어의 Keys 가 row 인 matrix 가 나오고, Value Score 는 얼마나 잘 대응되는지를 구한 값이다.
Attention Summary
- attention은 모델이 뭐가 중요한지 보기 위해서 추가된 레이어다
- Q, V, K 는 attention 레이어의 정보 검색에 사용된다.
- 유연한 시스템은 다른 언어간의 문법적 구조도 잘 매칭해서 찾을 수 있다.
2. Training an NMT with Attention
NMT Model Training concept 에 대해서 배운다.
Teacher Forcing
- 위에서 배운 시퀀스 투 시퀀스 과정 중에, 예측한 값이 틀린 값이면 어떻게 될까? 아마 다음 시퀀스도 망가질 것이다.
- 따라서 훈련시에는 Teacher Forcing 개념을 도입해서 ground truth를 우리가 예측한 값처럼 보고 학습한다. (선생님이 지도를 해줌)
- Teacher Forcing 을 통해서 더 빠르고 정확한 학습이 가능하다!

teacher forcing 에 대한 추가 자료 -> https://towardsdatascience.com/what-is-teacher-forcing-3da6217fed1c (Wong, 2019)
3. Evaluation for Machine Translation
NMT task 의 가장 큰 어려움 중 하나는 evaluation(평가) 이다. 이 강의에서는 BlEU Socre 와 ROUGE Score 를 소개한다.
(1) BLEU Score
- Bilingual Evaluation Understudy
- 'candidate' 텍스트를 1개 이상의 'reference' 번역과 비교해서 MT 의 퀄리티를 측정하는 평가방법이다.
- 0~1 사이 값으로, 1에 가까울 수록 성능이 좋다.
- 일반적으로 uni-gram ~ 4-gram 을 candidate와 reference로 사용한다.
- 단어의 의미와 문장 구조를 고려하지 않기 때문에 문제가 있음
유니그램 정밀도(Unigram Precision)
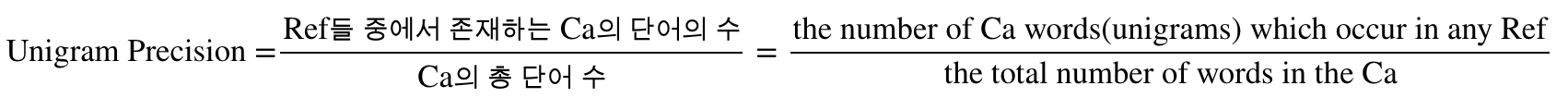
기계번역으로 번역되는 문장이 candidate 이고, 사람이 번역한 문장이 reference 임
(2) ROUGE Score
- Recall-Oriented Understudy for Gisting Evaluation
- generated text 와 human-created text 간의 precision, recall을 측정한 평가방법
- recall = 얼마나 참조 텍스트가 시스템 텍스트와 겹치는지
- precision = 얼마나 시스템 텍스트가 참조 텍스트와 겹치는지
- 수를 단순 비교하고, 의미는 고려하지 않는 문제점이 있음. 점수 계산 시에 유사어도 고려하지 못함
모델이 생성한 시스템 텍스트, 사람이 생성한 참조 텍스트
ROUGE Score - Recall 과 Precision


4. Sampling and Decoding
decoding은 encoder 의 hidden states 에서 모든 계산이 완료되고, 다음 토큰을 예상할 준비가 되어 있을 때 사용한다.
Decoder 에서 번역된 문장을 구성할 수 있는 두 가지 방법 (크게)-> Greedy Decoding 과 Random Sampling 이 있다.
(1) Greedy Decoding
- 직역한 뜻과 같이 모든 각 step에서 가장 가능성(우도, likelihood)가 높은 단어를 선택한다.
- 각 step 마다 가장 높은 확률을 고려하기 때문에 고른 단어가 긴 시퀀스에서는 best 단어가 아닐 수 있음
- 가장 간단함
(2) Random Samping
- 다음에 올 단어를 무작위로 선택하는 방법, 너무 무작위이기 때문에 가중치를 준다.
- 순서 확률에 따라 가중치를 다르게 부여한다.
- 빠름
Temperature
sampling 에서는 temperature 라는 하이퍼파라미터가 있다. 예측의 랜덤성을 조절한다. low temperature는 더 정확하고 안정적인 예측을 하고, high temperature 는 더 재밌고, 랜덤한 예측을 한다. 하지만 더 많은 실수를 한다.
(3) Beam search decoding
- 단어의 다음 확률이 높은 것으로만 문장을 구성하는 것은, 전체 문장으로 봤을 때 나쁜 선택일 수 있음 (Greedy decoding)
- 그래서 나온 것이 beam search decoding 인데, bfs 를 사용해서 좀 더 탐색적인 방법임
- 단순히 우도가 가장 높은 단어를 선택하는 것 대신, 조건부 확률을 기반으로 여러 옵션을 선택한다.
- beam search 의 B (beam 너비)가 파라미터로, 넓을 수록 모델의 성능은 향상되지만 디코딩 속도가 느려진다.
- beam search 의 문제는 정확하지 않은 분포를 학습할 수 있다는 것이다. 또한 single token 에 더 큰 weight를 주기도 한다. (filler word 'Uhm...' 으로 채우기도함) -> 부정확한 corpus를 가질 경우 문제가 더 심해진다.

토큰 I 가 할당 되었을 때, beam이 3이기 때문에 3개씩 조건부 확률로 선택 해나간다.
(4) MBR(Minimum Bayes Risk)

랜덤샘플을 생성하고 각각 다른 것들과의 유사성을 계산해서 golden one을 찾는다. (ROUGE score 같은 방법 사용) -> 모든 샘플에 대해 반복
MBR decoding 에 대한 설명이 충분하지 않아서 좀 더 찾아봐야할 것 같다.
'🤖 Today-I-Learned ] > Deep Learning' 카테고리의 다른 글
| Apple paper 모음 (1) | 2021.03.04 |
|---|---|
| CNN 의 특징 3가지 (0) | 2021.02.25 |
| [NLP] 단어부터 문장까지 GloVe Embedding / Clustering (6) | 2021.01.25 |
| [NLP] 딥러닝을 이용한 자연어 처리 입문 - Text Classification Questions 정리 (0) | 2020.11.24 |
| [논문 리뷰] Deep Residual Learning for Image Recognition - ResNet(1) (2) | 2020.03.31 |