Pytorch를 사용하면서 알게된 내용들, 정확히 이해하려는 코드들을 모아놓습니다.
Updated 21.10.07
1. TensorDataset의 사용
torch.tensor -> TensorDataset -> DataLoader
의 과정으로 깔끔한 코드를 작성한다.
from torch.utils.data import (DataLoader, TensorDataset)TensorDataset은 ds = TensorDataset(x,y) 뿐만 아니라 여러개의 데이터를 넣을 수도 있다.
# 보통 사용
ds = TensorDataset(x,y)
# 여러개 묶음 사용
train_features = TensorDatast(input, input_lengths, label, left_feature, right_feature)
train_dataloader = DataLoader(train_features, shuffle=True, batch_size=config["batch_size"])
이 후에 데이터로더에서 배치별로 가져올때 하나씩 가져다 쓰면되다
input, input_length, label, left_feature, right_feature = batch[0], batch[1], batch[2], batch[3], batch[4]
2. loss.item()의 사용
모델에서 계산된 loss 가 있다면, loss.item()을 통해 loss의 스칼라 값을 가져올 수 있다.
losses = []
# (생략)
losses.append(loss.item()) # 이렇게 사용
3. model.eval() vs with torch.no_grad()
https://discuss.pytorch.org/t/model-eval-vs-with-torch-no-grad/19615
가장 큰 차이는 backpropa 유무
model.eval()
- model의 모든 layer가 평가모드(eval)가 된다.
- 따라서 batchnorm, dropout이 평가모드에서도 일한다. (단, 평가모드로 일함. dropout은 평가모드에서 no opt가 된다.)
There is no such thing as “test mode”.
Only train() and eval().
Both bn and dropout will work in both cases but will have different behaviour as you expect them to have different behaviours during training and evaluation. For example, during evaluation, dropout should be disabled and so is replaced with a no op. Similarly, bn should use saved statistics instead of batch data and so that’s what it’s doing in eval mode.
torch.no_grad()
- batchnorm, dropout이 평가모드에서도 일 안한다.
- meory사용이 줄어들고 연산이 빨라지지만 backpropa 불가능
- (역전파 생각 안하고 빠른 연산을 위해 사용)
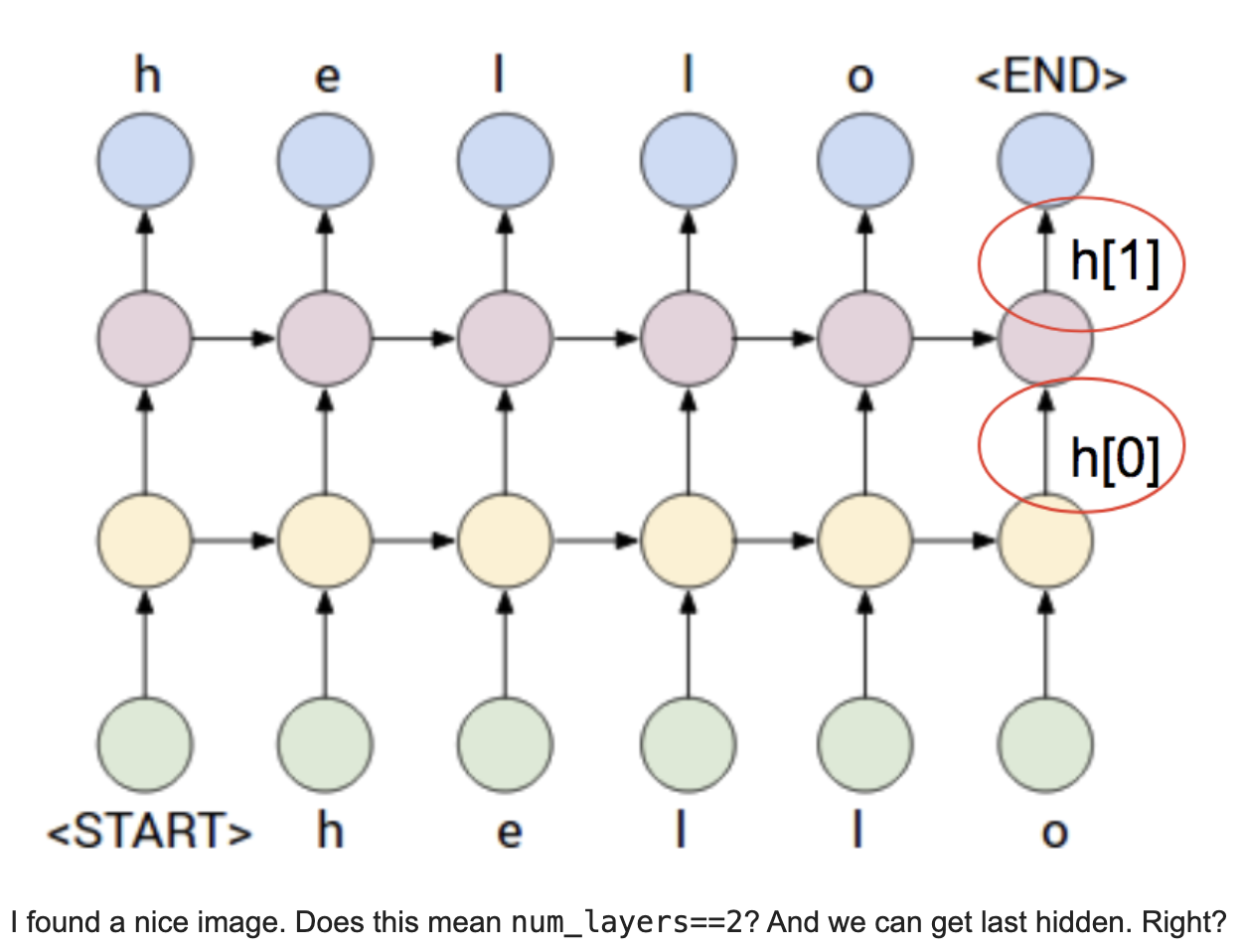
4. RNN Module들의 num_layers 옵션

https://discuss.pytorch.org/t/what-is-num-layers-in-rnn-module/9843
What is num_layers in RNN module?
Hi, I am not sure about num_layers in RNN module. To be clarify, could you check whether my understanding is right or not. I uploaded an image when num_layers==2. In my understanding, num_layers is similar to CNN’s out_channels. It is just a RNN layer wi
discuss.pytorch.org
num_layers in RNN is just stacking RNNs on top of each other. So you get a hidden from each layer and an output only from the topmost layer.
5. gradient cliping
rnn 계열의 그래디언트를 구할 때, 기울기가 너무 커지는 것을 방지 하기 위해서 사용
torch.nn.utils.clip_grad_norm_(parameters, max_norm, norm_type=2.0, error_if_nonfinite=False)torch.nn.utils.clip_grad_norm_ — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
5. 특정 레이어 freezing 시키기
frozen_list = [] # should be changed into torch.nn.ParameterList()
active_list = [] # should be changed into torch.nn.ParameterList()
def layer_freeze(model, layer_names):
frozen_list, active_list = [], []
for name, param in model.named_parameters():
for layer_name in layer_names:
if layer_name in name:
param.requires_grad = False
frozen_list.append(param)
else:
param.requires_grad = True
active_list.append(param)
optimizer = torch.optim.SGD([
# {'params': frozen_list, 'lr': 0.0},
{'params': active_list, 'lr': args.learning_rate}],
lr = args.learning_rate,
momentum = args.momentum,
weight_decay = args.weight_decay)https://discuss.pytorch.org/t/model-named-parameters-will-lose-some-layer-modules/14588/3
Model.named_parameters() will lose some layer modules
Thanks for the quick reply. My completed code looks like: param_frozen_list = [] # should be changed into torch.nn.ParameterList() param_active_list = [] # should be changed into torch.nn.ParameterList() for name, param in model.named_parameters(): if name
discuss.pytorch.org
'🔨 Trial and Error Log' 카테고리의 다른 글
| [PyCharm] 서버 자동 업로드가 안될 때 - PyCharm Deployment Auto upload (0) | 2021.10.29 |
|---|---|
| Huggingface(github 레포) 인용하기 (0) | 2021.10.07 |
| vs code snippet(스니펫) 공유 - 데이터분석, python (0) | 2021.06.28 |
| nlp-load map 2019 (3) | 2021.06.28 |
| 파이썬 @ 연산자 (2) | 2021.06.27 |